Hashmaps are essential data structures in programming. They store key-value pairs for fast data retrieval.
Understanding how a hashmap works internally is crucial for programmers and tech enthusiasts. It helps in grasping how data is stored, accessed, and manipulated efficiently. Hashmaps use a technique called hashing, which converts keys into unique indexes. This allows quick lookup times, making them popular in various applications.
Many interviewers ask this question to test your understanding of data structures. Knowing the inner workings of a hashmap can set you apart in technical interviews. This guide will explain the internal mechanics of hashmaps, providing you with the knowledge to confidently answer this interview question.
Decoding The Hashmap
A Hashmap is a widely used data structure. It stores data in key-value pairs. Understanding how it works helps in coding interviews. Let’s break down the internal workings of a Hashmap.
Core Concept Of Hashing
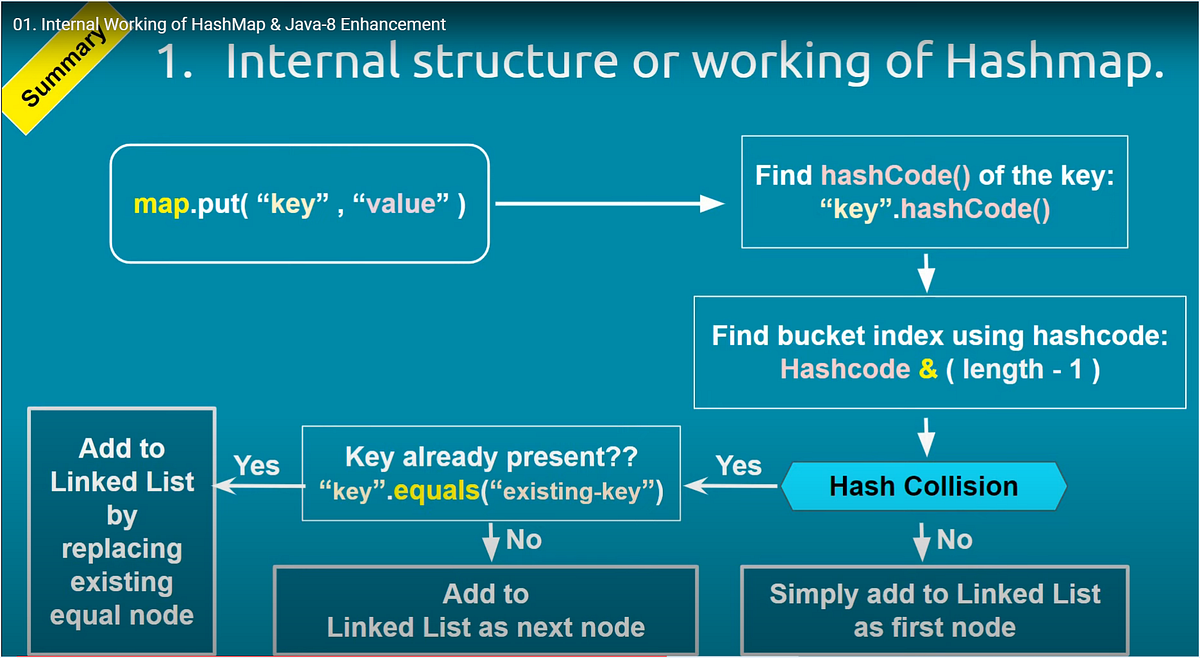
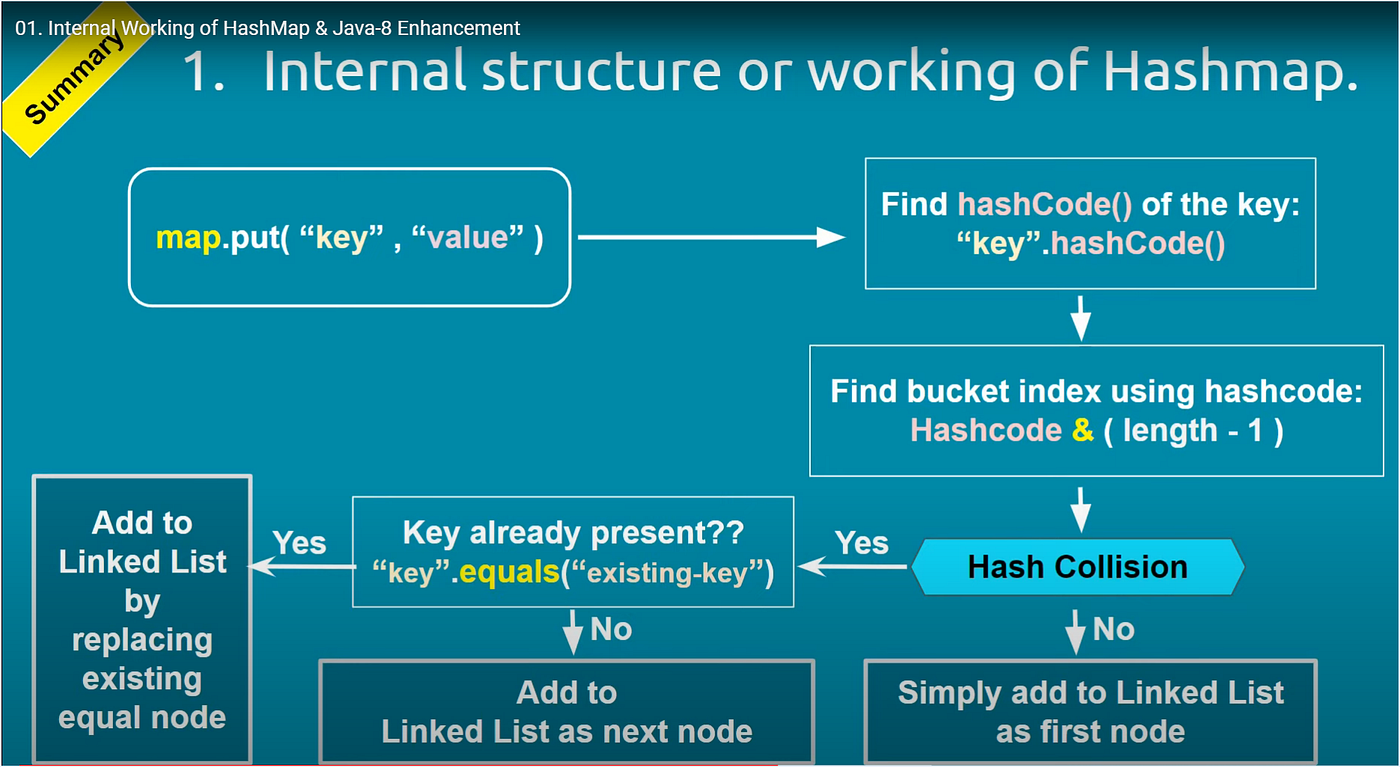
The core concept of a Hashmap is hashing. Hashing transforms data into a fixed-size value. This value is called a hash code. The hash code determines where to store the data.
- Key: The unique identifier for data.
- Value: The data associated with the key.
- Hash Function: Converts the key into a hash code.
The hash code maps to an index in an array. This makes data retrieval fast. If two keys generate the same hash code, a collision occurs. The Hashmap handles collisions using various methods.
Initial Creation Of A Hashmap
Creating a Hashmap involves several steps:
- Define the initial size of the array.
- Set the load factor. This is the threshold for resizing.
- Initialize the array to store entries.
Here’s an example of how a Hashmap is created in Java:
HashMap<string, integer=""> map = new HashMap<>(16, 0.75f); </string,>
| Parameter | Description |
|---|---|
| Initial Capacity | The number of buckets in the Hashmap. |
| Load Factor | Defines when to resize the Hashmap. |
With these parameters, a Hashmap efficiently manages memory. It can store and retrieve data quickly. Understanding these concepts prepares you for interviews. A clear grasp of Hashmaps helps in coding challenges.

Credit: m.youtube.com
The Role Of Buckets
Buckets play a crucial part in how Hashmaps work. They store data in a way that makes it easy to retrieve. Each bucket can hold multiple entries. This setup helps maintain quick access to information.
Understanding buckets helps in grasping the efficiency of Hashmaps. They help avoid confusion when storing data. Buckets organize data neatly, making lookups faster.
Bucket Structure And Indexing
Each bucket in a Hashmap is like a container. It holds key-value pairs. The index of a bucket is determined by the hash code of the key. This code is a unique number generated from the key.
Hashmaps divide data into different buckets based on this index. This division allows for quick access. When you search for a value, the hashmap checks the correct bucket first. This speeds up the process significantly.
Collision Handling In Buckets
Collisions can happen when two keys hash to the same bucket. This means they have the same index. Hashmaps handle this by using techniques like chaining or open addressing.
Chaining adds a list to each bucket. If a collision occurs, a new entry is added to this list. Open addressing finds another open bucket. Both methods help manage collisions and keep data organized.
Key-value Pair Storage
Hashmaps store data in a simple way. They use key-value pairs. A key is a unique identifier. The value is the data linked to that key. This system makes data retrieval fast and easy.
Every time you want to store or retrieve data, you use a key. This helps find the value quickly. Hashmaps are efficient. They can handle a lot of data without slowing down.
Storing Entries
Storing entries in a hashmap involves a few steps:
- Calculate the hash of the key.
- Map the hash to an index in an array.
- Store the value at that index.
Here’s how it works:
| Step | Description |
|---|---|
| 1 | Calculate hash using a hashing function. |
| 2 | Convert hash to an index for the array. |
| 3 | Store the value at the calculated index. |
This process ensures that each key maps to a specific value. It allows for quick lookups. The efficiency of this method is what makes hashmaps popular.
Linking Nodes
Sometimes, multiple keys hash to the same index. This is called a collision. Hashmaps handle collisions using linked nodes.
Each index in the hashmap can store a list of entries. This list holds all the key-value pairs that hash to the same index. Here’s how it works:
- A new entry is added to the list if a collision occurs.
- Each entry in the list has its key and value.
- Retrieving a value requires checking the list for the correct key.
This method helps maintain efficiency. Even with collisions, hashmaps can retrieve values quickly. The use of linked nodes keeps everything organized.
Understanding Hash Codes
Hash codes are vital for how a HashMap works. They help the map find and store data quickly. A hash code is a number generated from an object. This number is used to determine where to store the object in memory.
Hash Code Generation
Hash codes are created using the object’s data. Each class can define its way to generate a hash code. Here are some key points about hash code generation:
- Uses the hashCode() method.
- Returns an integer value.
- Should be consistent for the same object.
Here is a simple example:
public class Person {
private String name;
private int age;
@Override
public int hashCode() {
return name.hashCode() + age;
}
}Impact On Distribution
The hash code affects how objects are stored. Good distribution helps avoid collisions. A collision happens when two objects get the same hash code.
Consider these points:
- Even distribution leads to faster lookups.
- Poor distribution can slow down performance.
To illustrate:
| Hash Code | Object | Bucket |
|---|---|---|
| 123 | Person A | Bucket 1 |
| 456 | Person B | Bucket 2 |
| 123 | Person C | Bucket 1 |
Here, both Person A and Person C collide at Bucket 1. This can slow down retrieval times.
Resizing Mechanics
Understanding the resizing mechanics of a HashMap is important. It helps to know how it manages memory. Resizing occurs when the number of entries exceeds a certain threshold. This process ensures efficient data retrieval and storage. Let’s dive into the key steps involved in resizing.
Triggering A Resize
A HashMap triggers a resize when it reaches a certain load factor. The load factor is a measure of how full the HashMap is. The default load factor is typically 0.75. This means resizing happens when the number of entries exceeds:
| Condition | Calculation |
|---|---|
| Threshold | Current Capacity Load Factor |
For example, if the current capacity is 16, resizing will occur after 12 entries. This keeps the HashMap efficient and reduces collisions.
Rehashing Process
During the rehashing process, the HashMap creates a new array with double the size. All existing entries are then rehashed into this new array. The rehashing follows these steps:
- Create a new array with double the previous capacity.
- Iterate through each entry in the old array.
- Recalculate the index using the new array size.
- Place each entry in the new array.
This process ensures that entries are evenly distributed. It minimizes collisions, making data retrieval faster.
Rehashing can be resource-intensive. It is essential for maintaining performance. A well-managed HashMap performs better with fewer collisions.
Credit: ankitwasankar.medium.com
Concurrency In Hashmap
Hashmaps are widely used in programming. They allow quick data retrieval. But what happens during concurrent access? Multiple threads can read and write data at the same time. This can lead to problems. Understanding how Hashmaps handles concurrency is essential.
Handling Concurrent Modifications
Concurrent modifications can cause issues in Hashmaps. Here are the common problems:
- Data Corruption: If one thread modifies a Hashmap while another reads it, data may become inconsistent.
- Infinite Loops: A thread may enter an infinite loop if it tries to iterate over a Hashmap that is being modified.
- Exceptions: Threads may throw exceptions, like
ConcurrentModificationException, during operations.
To handle these issues, Java uses techniques like:
- Locking: Locks prevent multiple threads from accessing the Hashmap at the same time.
- Copy-on-Write: This creates a copy of the Hashmap for reading. The original remains unchanged.
Thread-safe Alternatives
There are safer alternatives to Hashmap for concurrent programming. Here are a few:
| Alternative | Description |
|---|---|
| ConcurrentHashMap | Allows concurrent access and updates without locking the entire map. |
| Collections.synchronizedMap | Wraps a Hashmap with synchronized methods to ensure thread safety. |
| CopyOnWriteArrayList | Creates a new copy of the list for every write operation, ensuring safe reads. |
These options provide better performance and safety in multi-threaded environments. Choosing the right tool is crucial for effective programming.
Performance Considerations
Understanding how Hashmaps perform is key. Several factors impact their efficiency. Two main areas to focus on are load factor and time complexity.
Load Factor’s Role
The load factor determines how full a Hashmap can get. It is the ratio of the number of entries to the number of buckets. A high load factor means more entries in fewer buckets.
This can lead to more collisions. Collisions happen when two keys hash to the same bucket. More collisions slow down performance.
A common load factor is 0.75. This balances space and speed. When the load factor exceeds this value, the Hashmap resizes. Resizing involves creating new buckets and rehashing existing entries.
Time Complexity Analysis
Time complexity shows how fast operations perform. Average-case time complexity for get and put operations is O(1). This means they are very fast.
In the worst-case scenario, time complexity can rise to O(n). This happens with many collisions. Thus, a good hash function is vital.
Choosing the right load factor also matters. A lower load factor can reduce collisions. This keeps operations running quickly.
Credit: ankitwasankar.medium.com
Common Misconceptions
Many people misunderstand how HashMaps works. This can lead to confusion. Knowing the truth can help you use HashMaps better. Let’s explore some common misconceptions.
Immutable Keys Importance
One major misconception is about the use of keys. Some think any object can be a key. This is not true.
Keys in a HashMap should be immutable. This means they cannot change. If keys change, it can cause issues. Here’s why this is important:
- Consistency: Immutable keys keep the data stable.
- Performance: Hashing works better with unchanging keys.
- Security: Immutable keys prevent accidental changes.
Using mutable keys can lead to problems. The HashMap may not find the correct value.
Hashmap Vs Hashtable
Another misconception is about HashMap and HashTable. Many think they are the same. They are not. Here are the key differences:
| Feature | HashMap | HashTable |
|---|---|---|
| Synchronization | Not synchronized | Synchronized |
| Null Keys | Allows one null key | No null keys allowed |
| Performance | Faster due to non-synchronization | Slower because it is synchronized |
| Legacy | Part of Java 1.2 | Part of Java 1.0 |
Understanding these differences helps in choosing the right one. Use HashMap for better performance when you don’t need synchronization. Choose HashTable when thread safety is necessary.
Frequently Asked Questions
How Does A Hashmap Store Data?
A Hashmap stores data in key-value pairs. It uses a hash function to calculate an index for each key.
What Is The Purpose Of A Hash Function In Hashmap?
The hash function helps find the right index quickly. It turns the key into a number, making data access fast.
Why Do Hashmaps Handle Collisions?
Collisions happen when two keys hash to the same index. Hashmaps use methods like chaining or open addressing to manage these.
Conclusion
Understanding how a hashmap works is important for coding interviews. It shows your grasp of data structures. We explored key concepts like buckets, collisions, and resizing. Knowing these details helps you answer questions confidently. Hashmaps are widely used for their speed and efficiency.
Mastering this topic can set you apart from other candidates. Keep practicing and stay curious. The more you learn, the better you will perform in interviews. Hashmaps may seem complex, but with the right knowledge, they become clear and manageable.
Keep studying, and you’ll excel.